AN INSURANCE CLIENT
2026-03-01
Project Background
With the in-depth advancement of digital transformation in the insurance industry, a large insurance company has continuously expanded its business scale and enriched its business scenarios, accumulating a vast amount of customer data, policy data, claims data and risk control data. To achieve efficient utilization of data assets and support core demands such as business analysis, risk control, and precise marketing, the company has initiated an enterprise-level data platform construction project.
During this process, the data warehouse (DW), CORE business system (CORE), ETL operating system and other business systems, as key nodes for data flow, are confronted with the following pain points:
Task scheduling is scattered, cross-system dependencies are chaotic, and data links are difficult to control.
The core scheduling nodes are at risk of single-point failure due to the lack of high availability guarantees.
Low operation and maintenance efficiency, difficulty in anomaly detection, and inability to ensure the continuity of data flow.
There is an urgent need for a professional scheduling management tool with high availability capabilities to achieve full-chain task scheduling and refined management. Therefore, the WLOADCTL scheduling platform is introduced to provide support for the stable operation of the enterprise-level data platform.
Technical Solution
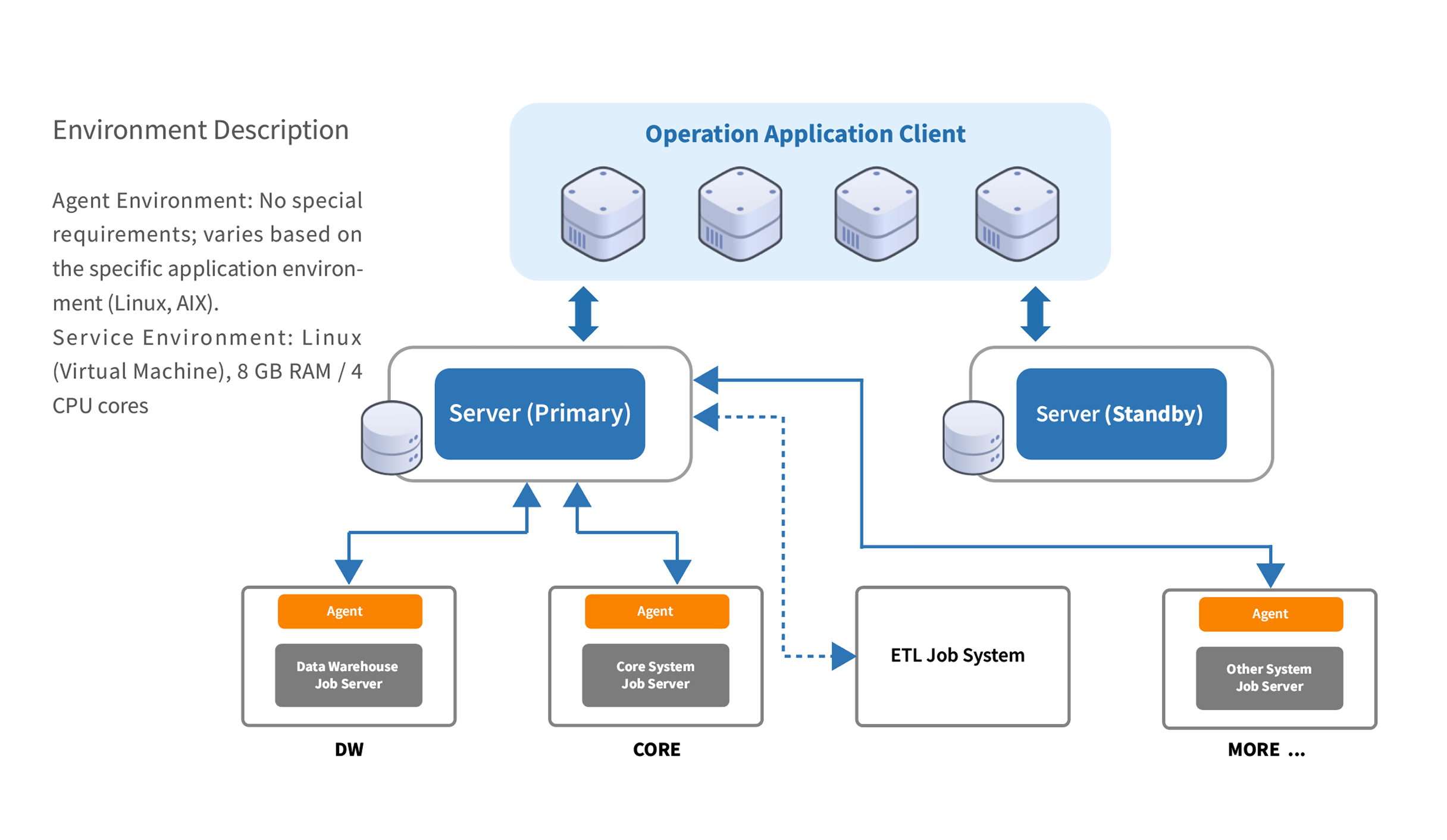
During the construction of the enterprise-level data platform, the insurance company adopted WLOADCTL to achieve full-chain, highly available task scheduling and management for its data warehouse and business intelligence analysis platform. The core implementation and delivery contents include:
A high-availability scheduling architecture with dual-active primary and backup
Deploy the WLOADCTL Primary and Standby dual-node service. The primary server (Primary) undertakes the daily scheduling work, while the standby server (Standby) synchronizes the status in real time. When the primary node fails, it can be quickly switched to ensure uninterrupted scheduling services and provide 7× 24-hour stable support for the data platform.
Unified scheduling and management across systems and platforms
Based on the lightweight Agent architecture, Agents are deployed at data warehouse (DW), CORE business system (CORE), and other business system nodes to achieve unified scheduling and management of massive batch processing data tasks across heterogeneous environments such as Linux/AIX, breaking down system silos.
Standardized orchestration of data link dependencies
Standardize and centralize the management of cross-stage data dependencies such as data collection, cleaning, transformation, and loading, clarify the execution sequence among the data warehouse, ETL operating system, and core business system, and ensure the continuity and correctness of the data flow.
Full-process visual monitoring and automated operation and maintenance support
Through a unified operation and maintenance client, the visual monitoring and traceability of the execution status of the entire process scheduling are achieved. At the same time, by integrating the health check mechanism of the primary and backup architecture, it can automatically identify and handle node anomalies, reduce the cost of manual intervention, and ensure the stable operation of the data processing link.
Application effect
The stability of scheduling has been significantly improved: The primary and backup dual-active architecture completely eliminates the single-point failure risk of the scheduling service, realizes the high availability operation of the core data platform, and ensures the continuity of the data link.
The cross-system scheduling capability has been comprehensively enhanced: The lightweight Agent architecture enables unified scheduling of heterogeneous environments such as data warehouses and core business systems, breaks down system silos, and enhances the efficiency of data flow.
The operation and maintenance efficiency has been significantly enhanced: The visual monitoring and automated operation and maintenance mechanism have enabled real-time tracking of task status and rapid location of anomalies, significantly reducing the manual operation and maintenance costs of data links.
The data support capacity has been significantly strengthened: The full-chain automation and standardization operation have significantly enhanced the processing efficiency and data quality of the data platform, providing efficient and reliable data support for core scenarios such as business analysis, precise marketing, and risk control of enterprises, and further strengthening the digital competitive edge of enterprises in the industry.