A CERTAIN DATA SERVICE PROVIDER
2026-03-01
Project Background
With the global development of the e-commerce industry, a large number of enterprises, brand owners and institutions need to obtain cross-platform and multi-dimensional data on products, prices and markets to support market analysis, price monitoring and decision-making. A certain large-scale data service provider is precisely the core provider of such data services, and its business scenarios have the following characteristics:
The data sources are scattered: It is necessary to connect with dozens of domestic and international e-commerce platforms such as Amazon, eBay, Walmart, and AliExpress, as well as various cloud environments like AWS, Azure, and DigitalOcean.
High task frequency: Multiple types of crawler tasks such as products, prices, and reviews need to be run simultaneously, which belongs to a high-frequency technical scenario.
Large data scale: The collected data needs to go through multiple steps such as cleaning, processing, and storage, forming a massive data processing flow.
Multi-tenant isolation: It is necessary to provide services for different clients such as governments, brand owners, and advertising agencies simultaneously, and requires that task scheduling be isolated from each other and not interfere with one another.
The traditional decentralized task scheduling and manual operation and maintenance mode are difficult to support such complex business requirements and are confronted with problems such as chaotic task scheduling, low collection efficiency, and poor stability of data links. To this end, the service provider has built a full-link scheduling platform based on WLOADCTL to achieve automated control from data collection to asset output.
Technical Solution
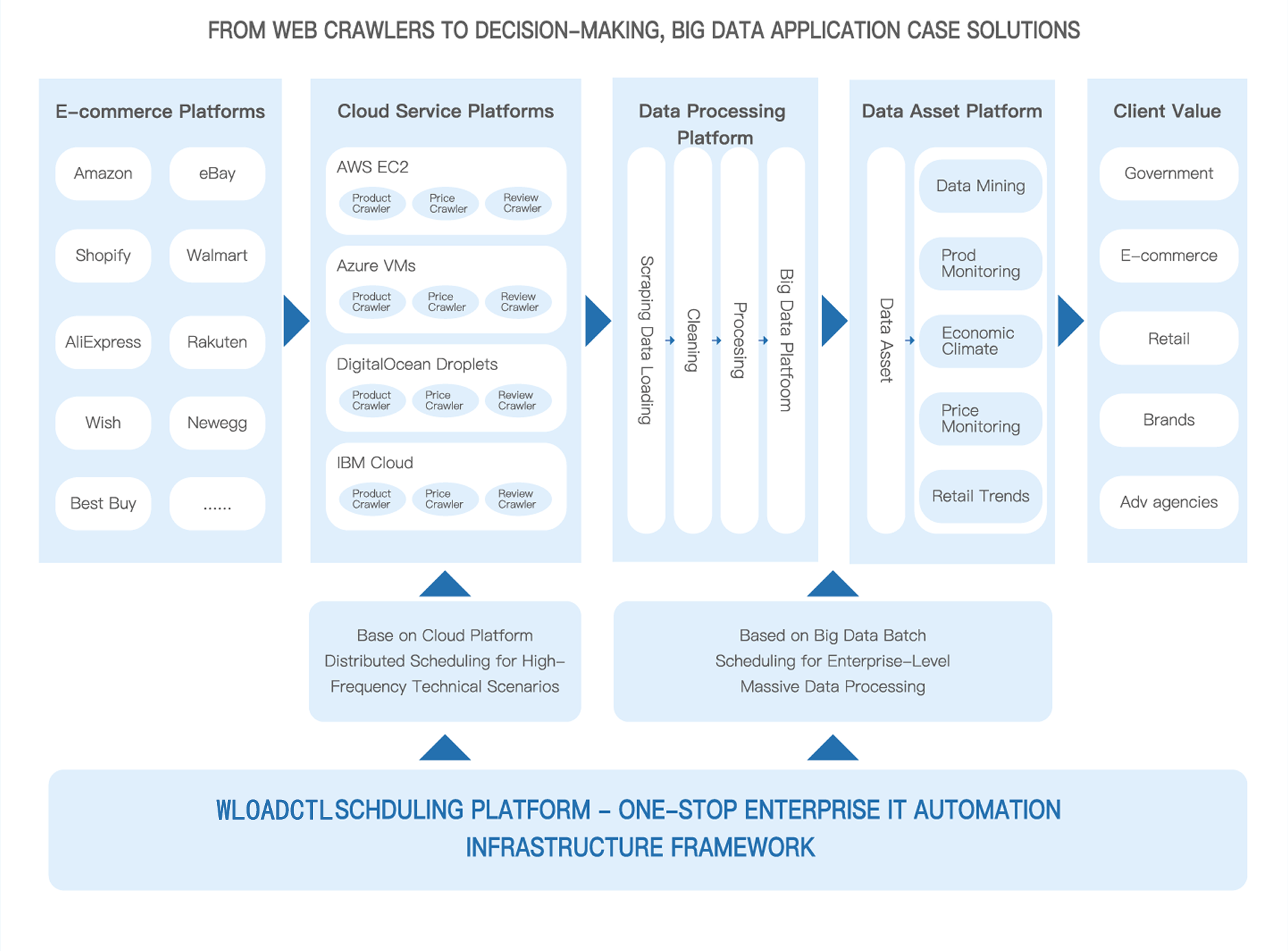
This data service provider has built an end-to-end scheduling system from "data collection to decision analysis" based on WLOADCTL. The core implementation contents include:
The cloud platform's distributed scheduling supports high-frequency collection scenarios
Relying on the distributed scheduling capability of WLOADCTL, parallel scheduling and centralized management of high-frequency tasks such as product crawlers, price crawlers, and review crawlers are achieved in multiple types of cloud environments such as AWS EC2, Azure VMs, and DigitalOcean Droplets, ensuring the stability and timeliness of cross-platform data collection.
The entire process of big data batch processing is fully automated
Realize the automated orchestration of the entire chain of tasks from "data collection and loading → data cleaning → data processing → big data platform warehousing", ensure the continuity and consistency of the data processing flow through unified scheduling, and support the enterprise-level massive data processing requirements.
Data assetization scheduling and application delivery
Dispatch downstream tasks such as data mining, product monitoring, price monitoring, and retail trend analysis in the data asset platform, and automatically push the processed structured data to customers, achieving full-process automated delivery from raw data to decision-making basis.
Multi-tenant isolation scheduling and operation and maintenance automation
Realize the isolated scheduling of data processing tasks for different customers to avoid resource competition and mutual influence among tasks. Meanwhile, through automated operation and maintenance capabilities such as system status inspection, log analysis, and abnormal alerts, the stable operation of the entire platform is ensured.
Application effect
Through the WLOADCTL scheduling platform, this data service provider has achieved full-process automation of e-commerce data business and obtained significant business value:
The collection efficiency has been significantly improved: High-frequency crawler tasks achieve distributed automated scheduling, significantly enhancing the coverage and timeliness of cross-platform data collection, and the data update frequency can stably meet customer demands.
The data processing link is stable and controllable: The batch processing flow of big data has achieved standardized scheduling, significantly reducing the error rate in data cleaning, processing, and warehousing, and greatly improving data quality.
The multi-tenant service capability has been significantly enhanced: The isolation scheduling mechanism ensures the independence of tasks for different customers, significantly improving service stability and customer satisfaction, and can support the simultaneous access of more industry customers.
The operation and maintenance costs have been significantly reduced: Operation and maintenance automation reduces manual intervention, enhances the efficiency of system inspection and anomaly handling, significantly lowers overall operation and maintenance costs, and also provides an expandable scheduling foundation for subsequent business scale expansion.